 Z.AI’s latest release posts state-of-the-art open-weight scores in coding, agentic tasks, and reasoning, challenging the assumption that proprietary models hold an unassailable lead.
Z.AI’s latest release posts state-of-the-art open-weight scores in coding, agentic tasks, and reasoning, challenging the assumption that proprietary models hold an unassailable lead.
Zhipu AI, the Beijing-based AI lab operating under the Z.AI brand, released GLM-5 this week — a 744-billion parameter open-weight large language model that represents one of the most significant leaps in open-source AI capability to date.
The model didn’t arrive quietly. Within hours of the announcement, Zhipu’s Hong Kong-listed stock (trading as Knowledge Atlas Technology) surged nearly 30%, closing at HK$405. The broader Chinese AI sector rallied alongside it, part of what’s being called “China open model week” — a concentrated wave of competitive releases from Chinese AI labs that has the industry recalibrating its assumptions about the open-source frontier.
GLM-5’s headline claim is direct: state-of-the-art performance among all open-weight models in the world on reasoning, coding, and agentic tasks, with benchmark scores that close the gap with — and in some cases exceed — proprietary systems from Google, OpenAI, and Anthropic.
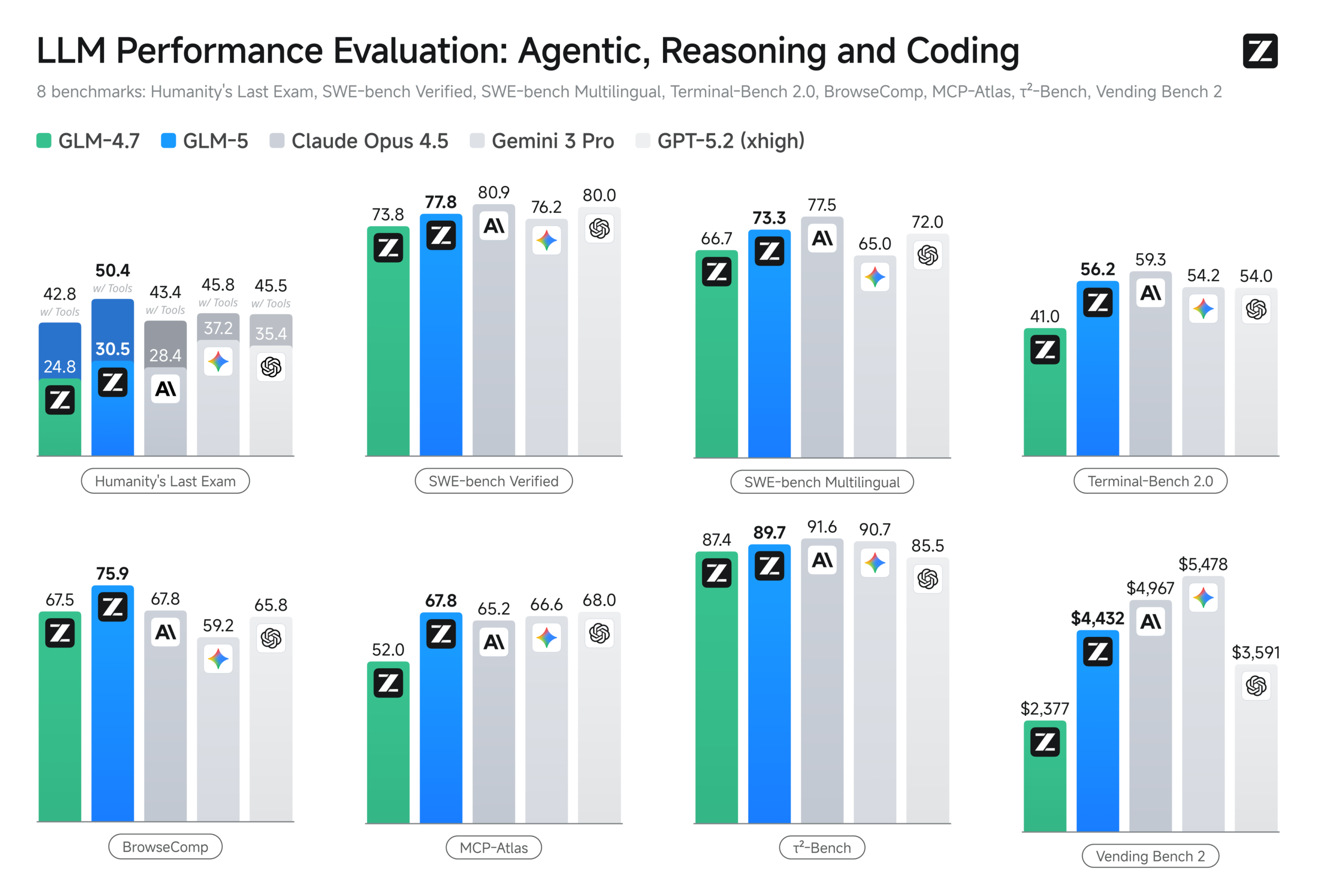
The benchmarks back it up.
The Numbers
GLM-5 represents a full architectural overhaul from Zhipu’s previous generation. The GLM-4.5 through 4.7 family operated at 355 billion total parameters with 32 billion active in a mixture-of-experts configuration. GLM-5 scales that to 744 billion total parameters with 40 billion active, trained on 28.5 trillion tokens — up from 23 trillion in the prior generation.
The model also integrates DeepSeek Sparse Attention (DSA), which reduces deployment costs while preserving long-context performance across a 200,000-token context window.
On SWE-bench Verified, the industry standard for evaluating real-world software engineering capability, GLM-5 scored 77.8. That places it ahead of Gemini 3 Pro (76.2) and Kimi K2.5 (76.8), and within reach of Claude Opus 4.5 (80.9) and GPT-5.2 at 80.0. For an open-weight model, that proximity to the proprietary frontier is significant.
On Terminal-Bench 2.0 using the Terminus 2 framework, GLM-5 posted 56.2 — ahead of GPT-5.2’s 54.0 and approaching Claude Opus 4.5’s 59.3. Through Claude Code evaluation, the same score of 56.2 landed just below Claude Opus 4.5’s 57.9.
Humanity’s Last Exam (HLE), a benchmark deliberately designed to challenge model limits, saw GLM-5 score 30.5 on the text-only subset, outperforming Claude Opus 4.5 at 28.4. With tool access enabled, the model jumped to 50.4 — the highest among open-weight models and ahead of both Claude Opus 4.5 (43.4) and GPT-5.2 (45.5) on the full set.
On the Artificial Analysis Intelligence Index v4.0, GLM-5 became the first open-weight model to score 50 or above, surpassing Google’s Gemini 3 Pro (48) and displacing Moonshot’s Kimi K2.5 Thinking as the top-ranked open model. Its agentic index score of 63 ranked third overall across all models tested, behind only Claude Opus 4.6 and GPT-5.2.
In agentic benchmarks specifically, the model posted leading open-weight scores across the board: 89.7 on τ²-Bench, 67.8 on MCP-Atlas, 43.2 on CyberGym, and 62.0 on BrowseComp — the last of which climbed to 75.9 with context management enabled.
Perhaps the most commercially relevant metric: GLM-5 achieved the lowest hallucination rate of any model tested on the AA-Omniscience Index, a 56-percentage-point reduction compared to GLM-4.7. The improvement came primarily from the model learning to abstain when it lacks confidence rather than generating plausible-sounding but incorrect answers — a capability gap that has kept enterprise adoption of AI systems in check across regulated industries.
From Vibe Coding to Agentic Engineering
Z.AI framed the release as a transition from “vibe coding” — the increasingly common practice of loosely describing desired functionality and letting an AI generate code — to what they call “agentic engineering.” The distinction matters.
Vibe coding works for prototyping and straightforward development tasks. Agentic engineering requires a model that can handle autonomous decision-making, long-horizon planning, multi-step debugging, and tool invocation across complex system-level tasks without constant human guidance.
GLM-5’s internal evaluations, conducted using the CC-Bench framework comparing GLM-4.7, GLM-5, and Claude Opus 4.5, showed substantial gains for the new model across frontend development, backend systems engineering, and long-horizon execution tasks. Z.AI reports that GLM-5 approaches Claude Opus 4.5 in both reliability and execution depth for real-world development workflows.
The model also demonstrated what Z.AI described as the ability to autonomously generate runnable code based on natural language descriptions across front-end, back-end, and data processing tasks. Its office automation capabilities — generating and manipulating PPTX, DOCX, and XLSX files — position it as a contender for the enterprise productivity workflows where AI adoption has the most immediate revenue impact.
The Infrastructure Innovation Behind the Model
A technical detail worth noting beyond the model itself: Z.AI developed and open-sourced Slime, a novel asynchronous reinforcement learning framework built specifically for GLM-5’s post-training.
Reinforcement learning at the scale of 744 billion parameters presents severe throughput bottlenecks with traditional synchronous approaches. Slime addresses this with asynchronous training infrastructure and an asynchronous agent RL algorithm that enables continuous learning from extended multi-step interactions. The framework substantially improved training efficiency and allowed more fine-grained post-training iterations than would otherwise be feasible.
Z.AI released Slime alongside the model weights, meaning the training infrastructure innovation is available independently — a contribution that could have broader impact on the open-source ecosystem than the model itself over time.
Market Context and Availability
GLM-5 arrives during a period of rapid-fire competitive releases from Chinese AI labs. Alongside Zhipu’s launch, companies including Minimax have released new models and agent products this week, creating what CNBC characterized as a rally across Chinese AI stocks.
The model is available under the MIT License on Hugging Face, through Z.AI’s API platform, and via third-party providers including Novita ($1/$3.20 per million input/output tokens), GMI Cloud, and DeepInfra ($0.80/$2.56). Self-deployment is supported through vLLM, SGLang, and xLLM, though the model’s 1.5TB native BF16 size requires substantial infrastructure — approximately eight GPUs at minimum using FP8 quantization and tensor parallelism.
Currently, GLM-5 supports text input and output only. Kimi K2.5 retains its position as the leading open-weight model with image input support.
What This Signals
GLM-5 doesn’t exist in isolation. It’s part of an accelerating pattern: open-weight models from Chinese AI labs reaching performance parity with proprietary Western systems across commercially important tasks, then releasing those models under permissive licenses.
For enterprise buyers and teams building AI-powered systems, the practical implications are concrete. The cost-performance gap between open-weight and proprietary options is narrowing in real time. Vendor lock-in calculus is shifting. And the range of capable deployment options — self-hosted, API, or hybrid — continues to expand.
The argument that frontier capability requires a proprietary model behind a paid API is becoming harder to sustain. That doesn’t mean proprietary systems have lost their advantages across every dimension. Claude Opus 4.5 and GPT-5.2 still lead on several benchmarks, and the infrastructure, tooling, and reliability ecosystems around those platforms remain substantial differentiators for many use cases.
But the distance is closing. And with open-weight models now beating Gemini 3 Pro on key intelligence indices and competing directly with the top proprietary systems on coding and agentic benchmarks, the trajectory is clear.
The frontier is no longer exclusive territory. And the organizations building AI strategies around that reality will be better positioned than those still assuming it’s a closed game.
GLM-5 is available now through the Z.AI API platform, on Hugging Face (zai-org/GLM-5), and through third-party inference providers. The model’s technical report is forthcoming.


